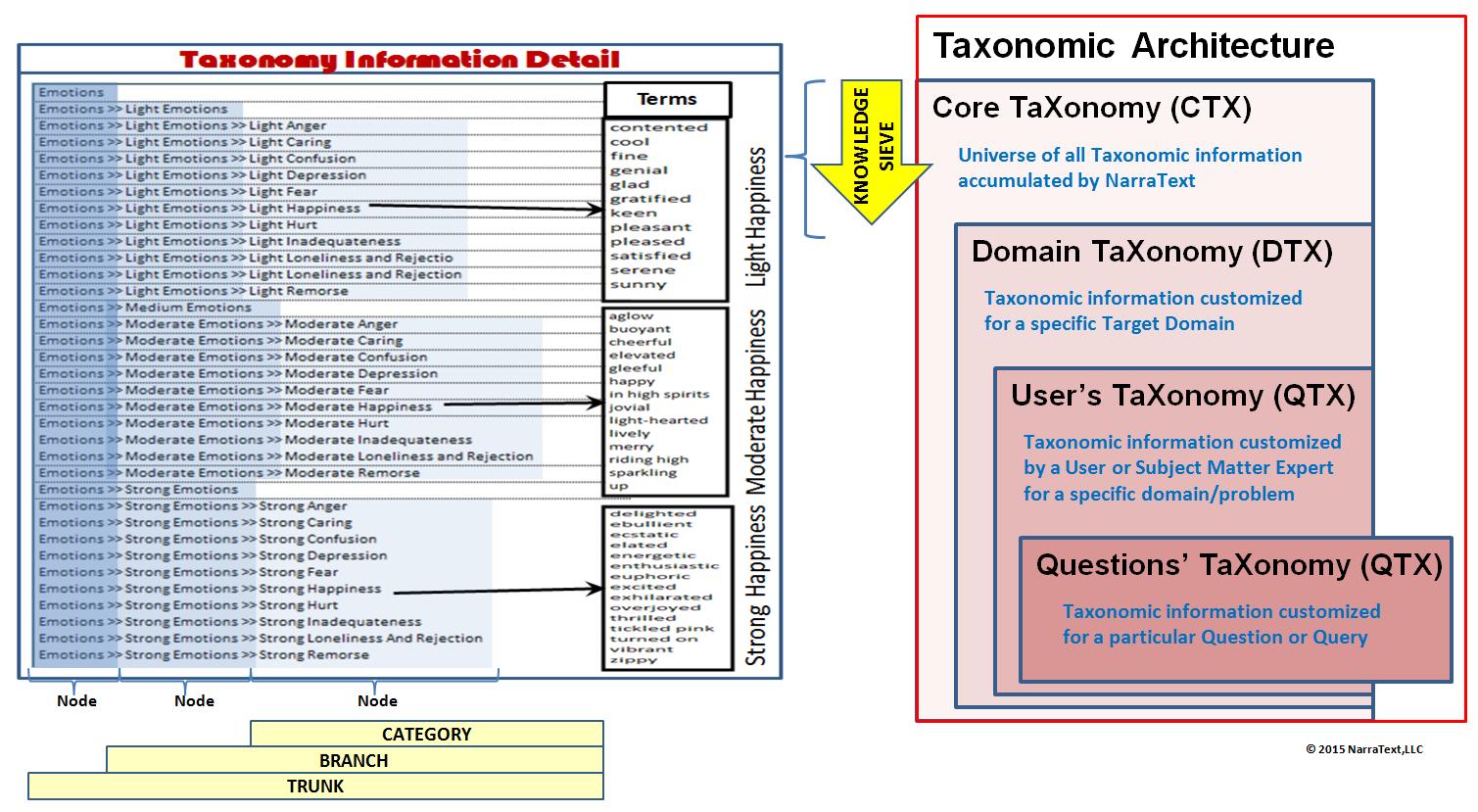
The
Taxonomic
Architecture is made up of
4-parts
listed in ascending order of precedence:
- Core
TaXonomy (CTX)- contains the (naive)
universe of all taxonomic information accumulated (and
being accumulated by) NarraText.
- Domain
TaXonomy (DTX) - contains a subset of CTX taxonomic
terms corresponding specifically to the target data set.
The DTX is created by filtering the union of
multiple CTX's
based on the terms (tokens and phrases) that are found in the
target data set. The filtering process is performed by an operation
known as the "Knowledge Sieve".
- User
TaXonomy (UTX) - contains Taxonomic
categories and terms defined by the Subject Matter Expert (SME) after
reviewing the semantics of the target dataset to extend, correct, or
enrich the dataset semantics.
- Question/query
TaXonomy (QTX) - contains taxonomic
categories and terms that are specifically tailored to the needs of a
given query or question
that is guiding the text extraction process. This provides a means to
enrich the semantics pertaining to obtaining a specific answer to a
business question.
The
Taxonomic
Information Detail shows an elaborated
hierarchy
(in list form) of categories that make up a specific taxonomy
(category set).
Three category branches within the shown hierarchy
have
arrows that point to term lists. Note that each branch consists of a
sequence of nodes separated by ">>". Terms are
assigned
(categorized) by "branch" this allows -- although
not
recommended -- creating multiple branches containing the same set of
nodes differing in sequene. For instance: the
branch
"Emotions>>Strong Emotions>>Strong Hurt ",
as a unique
branch category, can exist in the same taxonomy with a different (or
overlapping) set of terms as the branch:
"Emotions>>Strong
Hurt>>Strong Emotions".